Your users expect better search
The landscape of search and information retrieval is rapidly evolving. With the rise of AI and large language models, user expectations for search capabilities have skyrocketed. Your users now expect that your search can handle complex, nuanced queries that go beyond simple keyword matching. Just hear what Algolia CTO has to say -“We saw 2x more keywords search 6 months after the ChatGPT launch.” Algolia CTO, 2023They have 17,000 customers accounting for 120B searches/month. This trend isn’t isolated. Across industries, we’re seeing a shift towards more sophisticated search queries that blend multiple concepts, contexts, and data types. Vector Search with text-only embeddings (& also multi-modal) fails on complex queries, because complex queries are never just about text. They involve other data too! Consider these examples:
- E-commerce: A query like “comfortable running shoes for marathon training under $150” involves text, numerical data (price), and categorical information (product type, use case).
- Content platforms: “Popular science fiction movies from the 80s with strong female leads” combines text analysis, temporal data, and popularity metrics.
- Job search: “Entry-level data science positions in tech startups with good work-life balance” requires understanding of text, categorical data (industry, job level), and even subjective metrics.

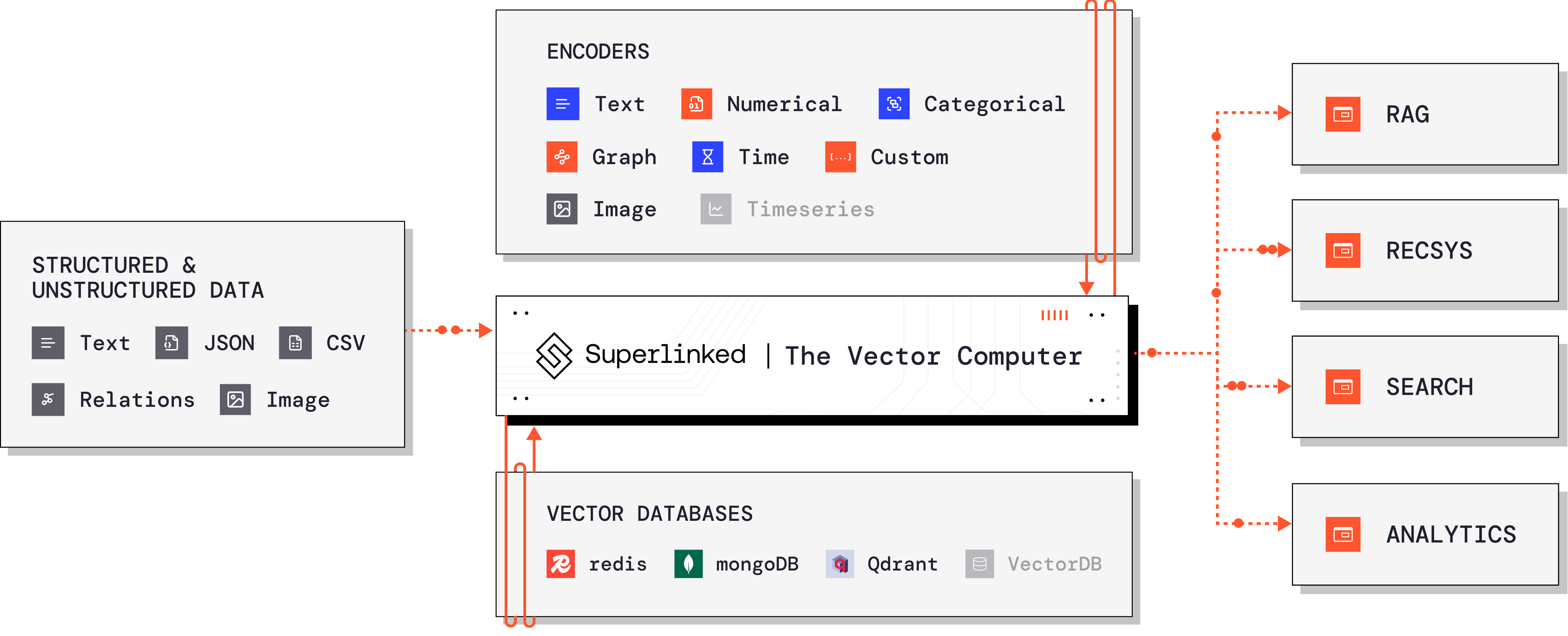
Enter Superlinked
This is where Superlinked comes in, offering a powerful, flexible framework designed to handle the complexities of modern search and information retrieval challenges. Superlinked is a vector embedding solution for AI teams working with complicated data within their RAG, Search, Recommendations and Analytics stack. Let’s quickly go through an example. Keep in mind that there are a ton of new concepts thrown at you, but this is just to illustrate how Superlinked ‘looks’. We’ll go over each concept in detail in the following sections. Imagine you are building a system that can deal with a query like"recent news about crop yield". After collecting your data, you define your schema, ingest data and build index like this:
Define your schemas
Create schema objects that define the structure of your data, including News, User, and Event entities.
Schema definition code
Schema definition code
Create embedding spaces
Define different types of embedding spaces that will capture various aspects of your data: recency, popularity, trust, and semantic similarity.
Encoder definition code
Encoder definition code
Build your index
Combine all the embedding spaces into a single index and define effects that capture user behavior patterns.
Index definition code
Index definition code
Define parameterized queries
Create flexible queries that can be customized at runtime with different weights and parameters.
Query definition code
Query definition code
Set up the execution environment
Configure your executor to run either in memory for development or with production vector databases.
Executor setup and API usage
Executor setup and API usage
But can’t I put all my data in json, stringify it and embed using LLM?
Stringify and embed approach produces unpredictable results. For example (code below):- Embed 0..100 with OpenAI API
- Calculate and plot the cosine similarity
- Observe the difference between expected and actual results

Okay, But can’t I …
1. Use different already existing storages per attribute, fire multiple searches and then reconcile results?
Our naive approach (above) - storing and searching attribute vectors separately, then combining results - is limited in ability, subtlety, and efficiency when we need to retrieve objects with multiple simultaneous attributes. Moreover, multiple kNN searches take more time than a single search with concatenated vectors.It’s better to store all your attribute vectors in the same vector store and perform a single search, weighting your attributes at query time.Read more here: Multi-attribute search with vector embeddings
2. Use Metadata filters or Candidate re-ranking
When you convert a fuzzy preference like “recent”, “risky” or “popular” into a filter, you model a sigmoid with a binary step function = not enough resolution.Semantic ranking & ColBERT only use text, learn2rank models need ML Engineers.
Broad queries eg “popular pants” can’t be handled by re-ranking at all, due to poor candidate recall.
Okay, seems like Superlinked proposes a nice approach, but
- How can I build with it at scale? The Superlinked Server is a deployable component available as a Python package on PyPI, designed to enhance the operation of Superlinked by providing a RESTful API for communicating with your application. This package streamlines the integration of Superlinked’s sophisticated search functionalities into existing applications by offering REST endpoints and Vector Database connectivity. It enables developers to focus on leveraging Superlinked’s capabilities without the burden of infrastructure management, from initial prototype to full-scale production.
How does it fit in the big picture?